2025-02-12
Multimodal Data Annotation for Automotive: A Practical Guide
How multimodal data annotation for automotive ML powers ADAS and autonomous driving — sensor fusion, LiDAR, QA workflows, and ROI explained.
Multimodal Data Annotation for Automotive: A Practical Guide
Multimodal data annotation for automotive is the process of labeling synchronised camera, LiDAR, radar, GPS, and IMU streams so perception models can detect, classify, and predict the behaviour of objects on the road. It is the foundational input for every modern automotive machine learning pipeline — from lane-keeping assist to Level 4 autonomous driving — because no single sensor sees the world completely.
Why Multimodal Annotation Defines Automotive Machine Learning
Single-sensor perception is brittle. A camera misreads glare; LiDAR struggles in heavy rain; radar lacks resolution. Sensor fusion — combining inputs from multiple sensors — solves this, but only when the training data is annotated consistently across those sensors at the same instant in time.
That cross-modal consistency is where most annotation programs break down. A pedestrian labelled in a camera frame must correspond to the exact 3D cuboid in the LiDAR point cloud and the same radar return, frame after frame, at 10–30 Hz. Get that wrong and your perception stack learns contradictions.
Three properties separate automotive-grade annotation from generic computer vision labeling:
- Temporal synchronisation — labels must align across sensors to sub-millisecond accuracy.
- Geometric consistency — a 3D box in LiDAR must project correctly into the 2D camera image.
- Taxonomy depth — automotive taxonomies routinely exceed 200 object classes, with attributes for occlusion, truncation, motion state, and intent.
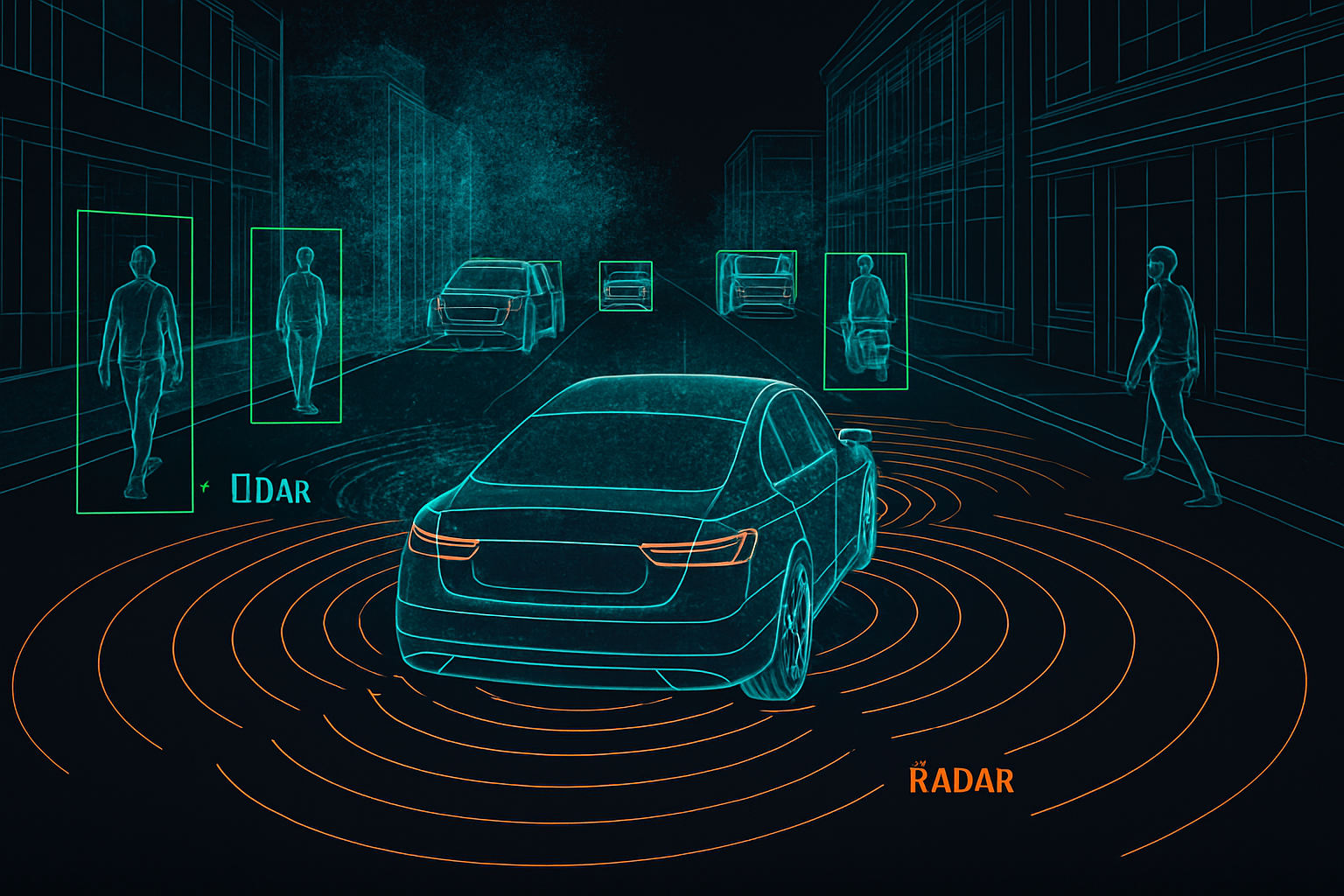
What Are the Different Types of Data Annotation Used in Autonomous Vehicles?
Autonomous vehicle (AV) datasets typically combine six annotation primitives, each tuned to a sensor modality and a perception task:
- 2D bounding boxes — fast object detection in camera frames; the baseline for ADAS object detectors.
- Semantic segmentation — pixel-level class labels (road, sidewalk, vegetation, vehicle) for drivable-area and scene-understanding models.
- Instance segmentation — pixel-level labels that also distinguish individual objects of the same class.
- 3D cuboids on LiDAR point clouds — oriented bounding boxes with length, width, height, and yaw, used for distance and velocity estimation.
- Polylines and splines — lane markings, curbs, and road edges for lane-keeping and HD map generation.
- Keypoints — pedestrian pose, traffic-sign corners, and vehicle wheel contacts for fine-grained behaviour prediction.
A production AV dataset uses all six on the same scene, linked by a unique object ID that persists across sensors and time. This is what makes LiDAR annotation for automotive materially harder than labeling a still image — every annotator decision is multiplied by the number of frames and sensors it touches.
How Does Multimodal Annotation Improve Autonomous Driving Safety?
Safety in autonomous driving is a function of perception recall on the long tail — the rare events that crash a model trained only on common scenes. Multimodal annotation improves safety in four measurable ways:
- Redundancy under sensor failure. When the camera is blinded by sun, a model trained on fused labels can still localise the object using LiDAR and radar.
- Better depth and velocity estimates. LiDAR provides ground-truth distance; radar provides ground-truth Doppler velocity. Cross-labeling these against camera classes teaches the model to reconcile them.
- Higher precision on small or distant objects. A pedestrian 80 metres away may occupy only a few camera pixels but dozens of LiDAR points — joint annotation prevents misses.
- Reduced false positives in ADAS. Automatic emergency braking systems depend on multi-sensor agreement; multimodal labels train the model to require it.
The net effect is a measurable lift in mean Average Precision (mAP) on rare classes and a reduction in phantom braking events — the failure mode most cited in ADAS recalls.
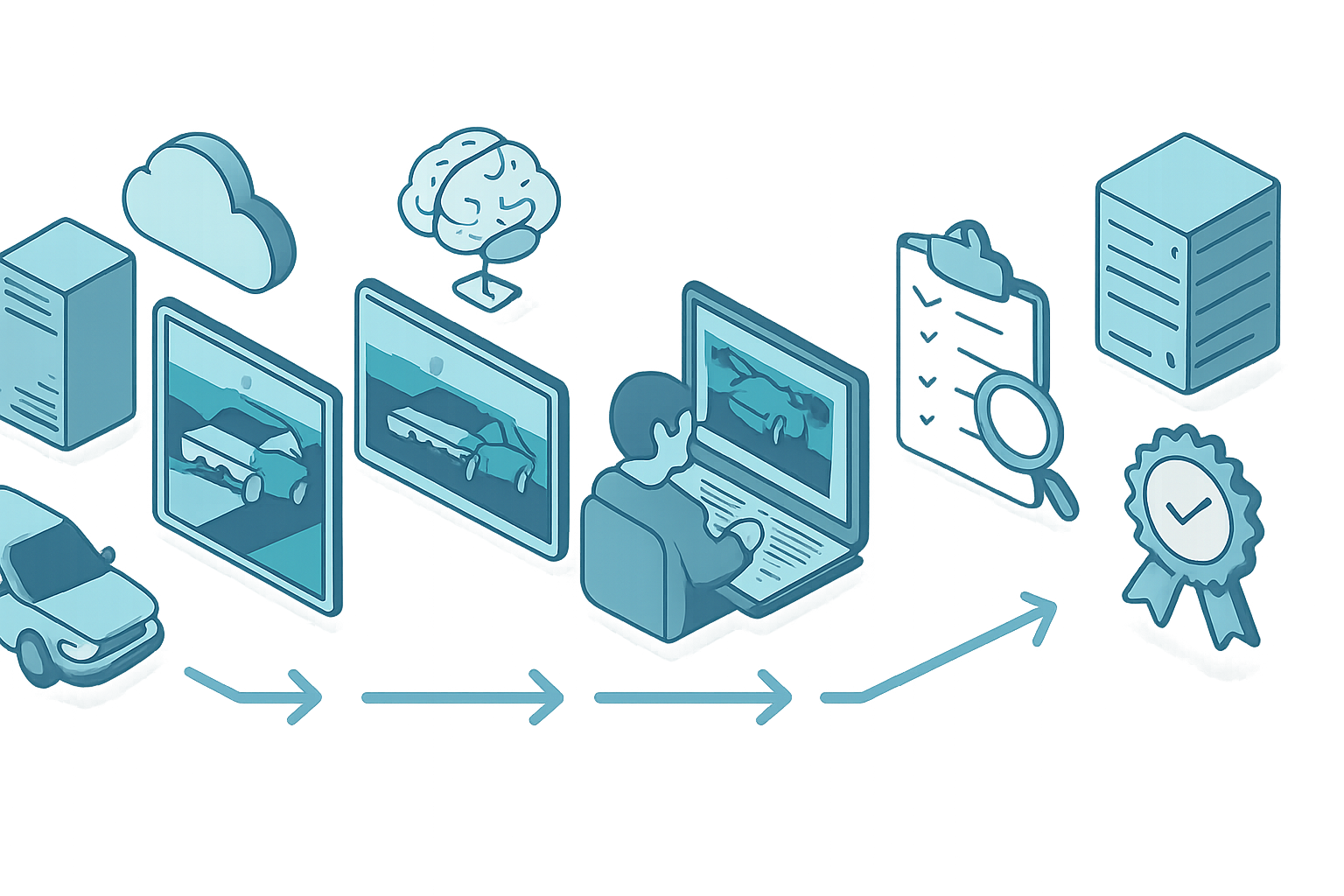
The Sensor Fusion Annotation Workflow
A defensible automotive AI training data pipeline runs through six tightly coupled stages. ASPL's PIXEAL platform implements each as a governed, auditable step:
- Ingestion and calibration check. Verify that extrinsic and intrinsic calibration matrices are present and correct; reject sequences where sensor timestamps drift beyond tolerance.
- Scene segmentation. Split long drives into 10–30 second clips containing meaningful events (intersections, merges, pedestrian crossings).
- AI-assisted pre-labeling. Run a baseline 3D detector and 2D segmentation model to produce candidate labels — typically cutting annotator effort by 50–70%.
- Human annotation with cross-modal projection. Annotators correct labels in a unified 3D + 2D viewer; every 3D cuboid is auto-projected into the camera view for instant geometric validation.
- Multi-stage quality assurance. Inter-annotator agreement (IAA), geometric consistency checks, temporal smoothness scoring, and model-in-the-loop disagreement sampling.
- Governed delivery. Datasets are exported in nuScenes, KITTI, or custom schemas through secure ODC (Offshore Development Centre) environments with full lineage.
Skipping the calibration check at step one is the single most common reason production datasets fail downstream — labels look correct in isolation but fall apart under sensor fusion training.
What Tools and Platforms Are Best for Automotive Data Annotation?
The market includes generalist platforms (CVAT, Labelbox, SuperAnnotate, V7) and automotive-focused tools (Encord, Keylabs, PIXEAL, Scale Nucleus). Selecting one depends on five criteria:
- 3D point cloud support with cuboid interpolation and ground-plane fitting.
- Synchronised multi-sensor viewers that show LiDAR and camera side-by-side with linked playback.
- Automation depth — pre-labeling models, auto-tracking across frames, and active learning loops.
- QA tooling — IAA scoring, gold-set benchmarking, and statistical sampling.
- Compliance posture — ISO 27001, SOC 2, and GDPR-aligned controls for personally identifiable information (PII) in driving footage.
ASPL's PIXEAL annotation platform was designed against these criteria specifically for automotive workloads, with native sensor-fusion viewers, custom-model integration for pre-labeling, and the QA gates required for safety-critical perception programs. For teams that need the platform plus the annotation workforce and governance, our AI data annotation services deliver the full pipeline end-to-end.
What Is the Role of Data Annotation in ADAS?
ADAS (Advanced Driver Assistance Systems) features — lane-keeping assist, adaptive cruise control, automatic emergency braking, blind-spot monitoring, traffic-sign recognition — are all supervised learning problems trained on labeled multi-sensor data. Each feature consumes a slightly different slice of the annotation taxonomy:
- Lane-keeping assist needs precise polyline annotation of lane markings, including dashed/solid attributes and merge geometry.
- Automatic emergency braking requires 3D cuboids on vehicles and pedestrians with accurate velocity vectors derived from frame-to-frame tracking.
- Pedestrian detection depends on dense bounding boxes plus keypoint pose to predict intent (about to cross vs. standing still).
- Traffic-sign recognition uses fine-grained classification with attribute labels for sign type, condition, and occlusion.
- Collision avoidance fuses all of the above, plus radar tracks, to estimate time-to-collision.
The accuracy ceiling of every one of these features is set by annotation quality. A model cannot exceed the consistency of its labels.
Quality Metrics That Actually Predict Model Performance
Most annotation vendors report a single accuracy figure. That number is meaningless in automotive contexts. The metrics that correlate with downstream model performance are:
- Inter-annotator agreement (IAA) — measured as Cohen's kappa for classes and IoU (Intersection over Union) for geometry; target ≥0.95 for safety-critical classes.
- Geometric reprojection error — the pixel distance between a 3D cuboid projected into the camera and the corresponding 2D box; target ≤2 pixels at typical resolutions.
- Temporal stability — variance in object dimensions across consecutive frames; sudden jumps indicate annotation drift.
- Edge-case coverage — proportion of the dataset containing rare conditions (night, rain, construction zones, emergency vehicles).
- Gold-set accuracy — annotator performance against a held-out, expert-labeled benchmark, sampled continuously.
PIXEAL surfaces all five in real time so program managers can intervene before bad labels reach training.
The ROI Case for Outsourced Multimodal Annotation
Building an in-house multimodal annotation team for an AV program typically requires 40–80 trained annotators, 5–10 QA leads, sensor-fusion tooling, and a compliance framework — a £3–6M annual run-rate before a single label is produced. Outsourced annotation collapses that into a variable-cost line item with three measurable advantages:
- Faster ramp. A specialist partner can scale to thousands of hours of labeled drive data per week within four to six weeks.
- Predictable accuracy. Mature QA pipelines deliver consistent IAA across vendors and shifts, removing the variance of in-house hiring cycles.
- Compliance inheritance. ISO 27001 and GDPR controls are already in place; you inherit them rather than building them.
The break-even point for outsourcing is typically reached at around 500,000 annotated frames per year — well below the volume any serious AV or ADAS program consumes.
Bringing It Together
Multimodal data annotation for automotive is no longer a back-office function. It is the data layer that determines whether a perception stack ships, gets recalled, or wins on safety benchmarks. The teams that win treat annotation as a measured, governed, AI-assisted engineering discipline — not a manual chore.
ASPL's PIXEAL platform and annotation services were built for exactly this — sensor-fusion-native tooling, domain-specialist annotators, ISO-aligned governance, and QA metrics that predict model performance. If you are scoping a new ADAS feature, an AV perception model, or a fleet-data annotation program, talk to our annotation team and we will scope a multimodal dataset around your sensor stack, taxonomy, and accuracy targets.